
Today, Netflix open-sourced Polynote, the internal notebook they developed, to the public. It’s not rare these days that big tech companies open sources their internal tools or services, then got popular and adopted by the industry. Amazon AWS, Facebook’s React.js, etc. are two of them. It makes sense. These big tech companies have the best engineers in the industry and more often than not they are facing the biggest challenges that will drive the development of great tools. Netflix’s Polynote could be another one of those great tools and the data science/machine learning industry does need better tools in terms of how to write code, experiment algorithms and visualize data. Here are several things you need to know about this new tool. I’ll try to keep this succinct and to the point so you can quickly read through it and be knowledgeable about the pros and cons of this new choice of our development/research environment.
Polynote is more like a simple version of IDE rather than nicer version of a REPL
auto-completion, error indication, better text editor, LaTex support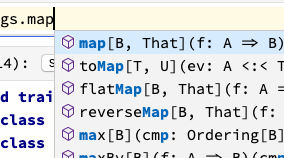

Polynote put some emphasis on making the notebook work more like an IDE or code editors like VS Code. It supports better auto-completion, linting, rich text editor, and LaTex. This might be a bit of an overstatement, but that’s the direction it is going. You can say better syntax highlighting and better auto-completion are trivial, but these little quality-of-life improvements could go a long way and make you focus more on the real tasks. BTW, most of the editing capabilities are powered by the Monaco editor which powers the experience of Visual Studio Code, showing potential to be even better.
Multi-language Support
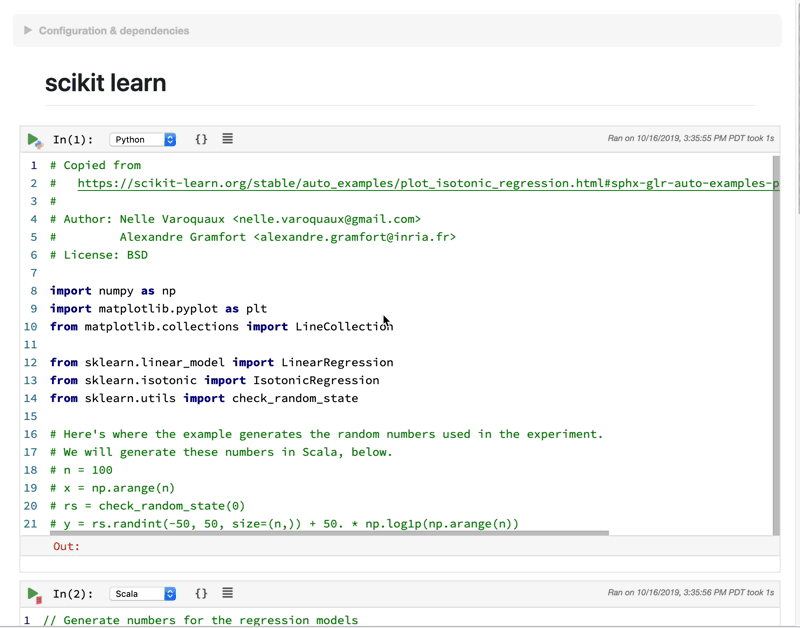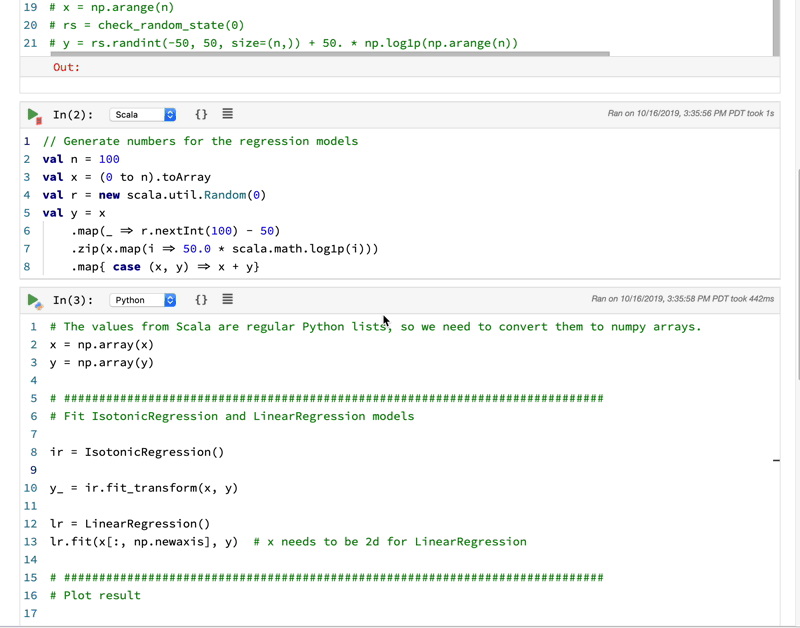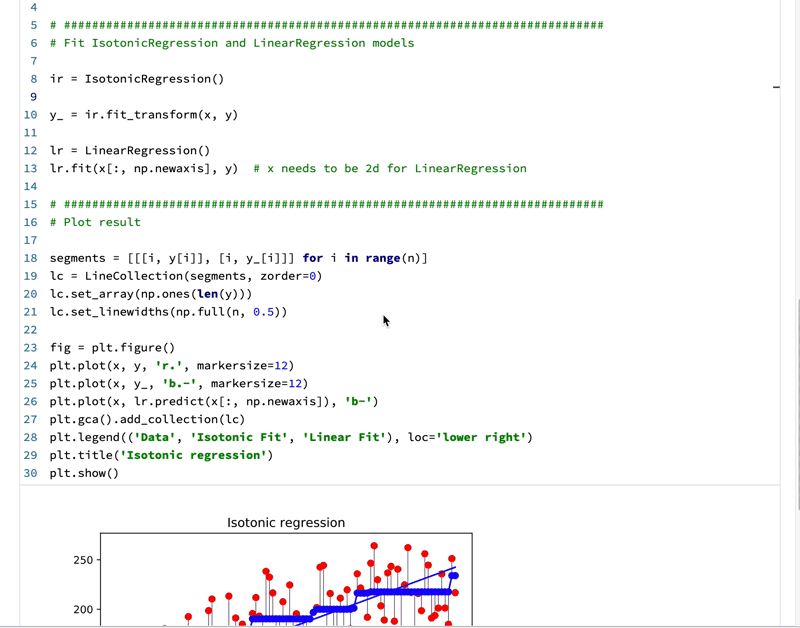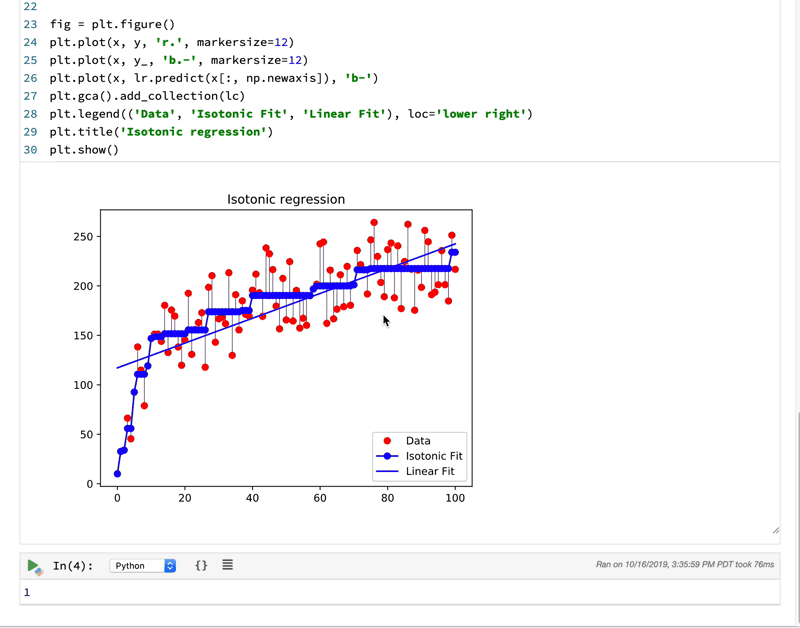
Currently, it only supports Python, Scala, and SQL. You might argue that Jupyter Notebook also supports Python, R, and Julia. But how they support multi-languages is different. For Jupyter Notebook, you can only choose one language for one notebook. Whereas Polynote can support all these languages working seamlessly in one notebook. It achieves this by sharing variables between cells so different language cells can work under same context. Needless to say, this has the potential to be very powerful. With more languages it supports, a skilled data scientist can use the best language for the right tasks. It increased the skill-cap yet also raise the performance bar.
Data Visualization and Data Awareness
In Polynote, data visualization is built-in. It means developers won’t need to write any code to visualize their data, they can just use a GUI interface and see the data the way they want. Also, developers won’t need to type in any code in order to see the value of the variable, you can just use the GUI. When code is running, there is also a progress window at the right side of the screen so you always have an idea of which part of the code is currently running.

These will all add up to better data intuition.
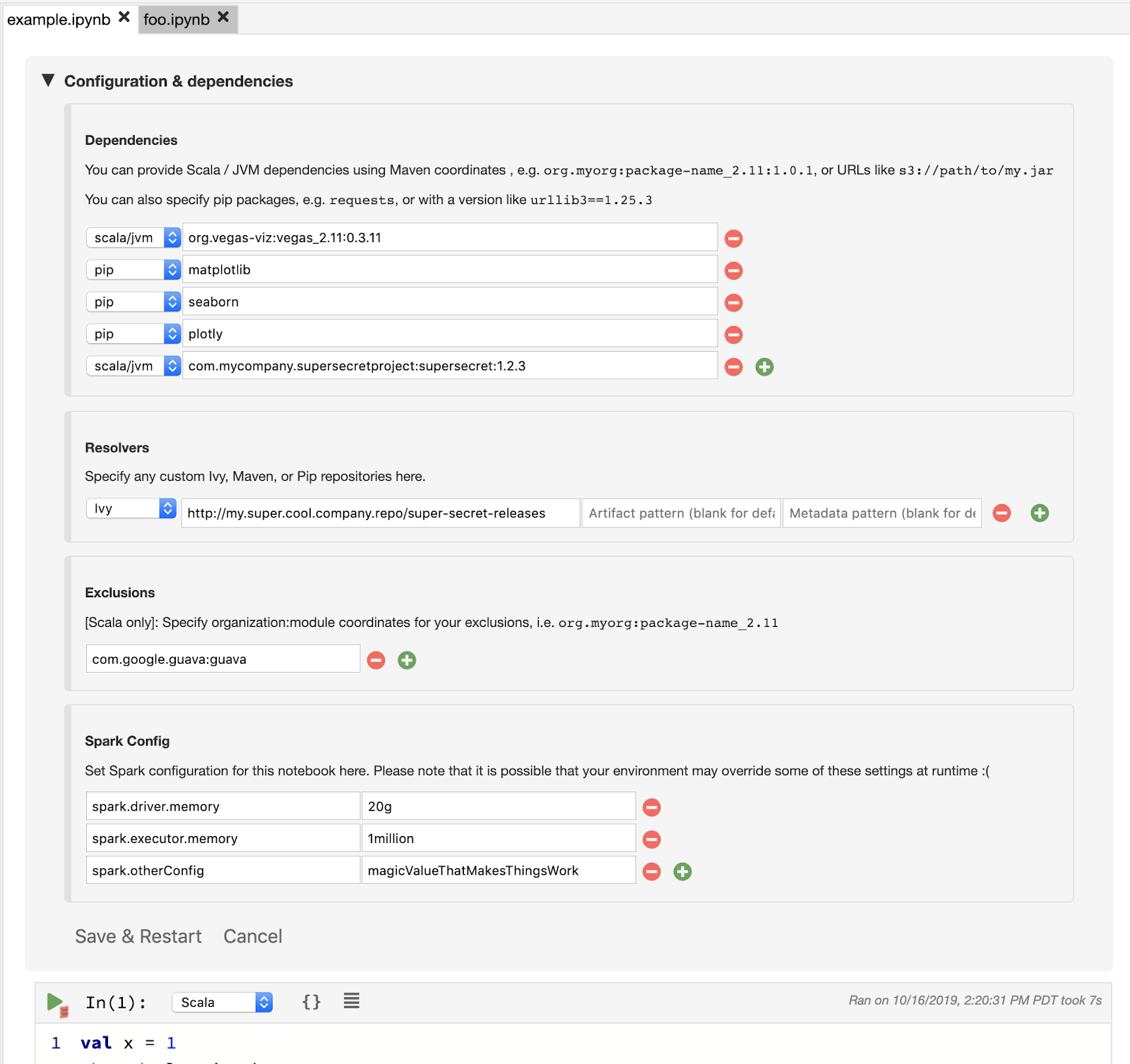
Configuration and dependency management built-in
Another quality-of-life improvement. Gone of the days you have to run things like:
! pip install packages
You can simply specify what dependencies you need for your code to run smoothly and BOOM, Polynote will set it up for you. This will result in less clutter in code. How good is that!
Reproducible Code
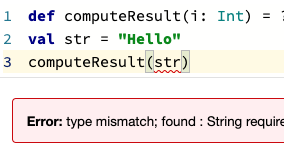
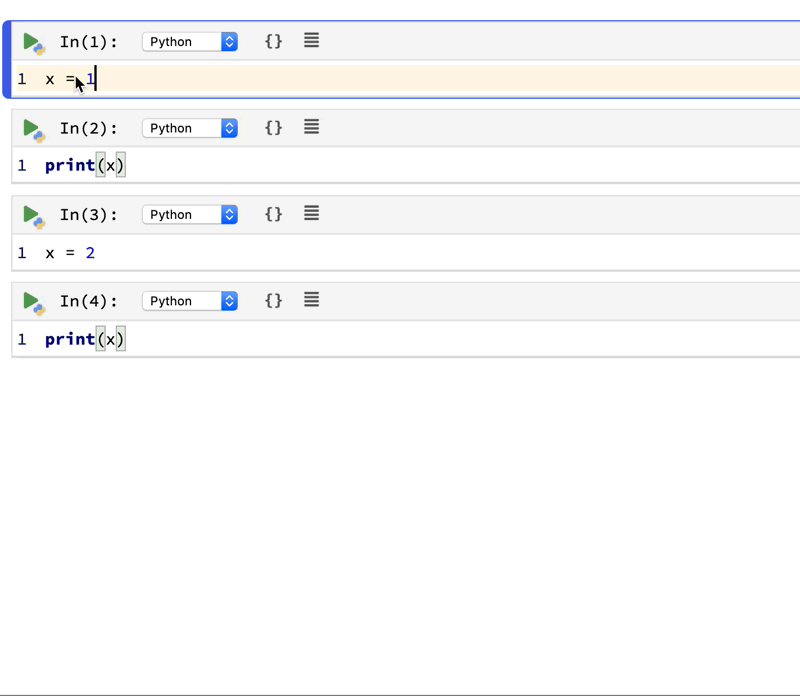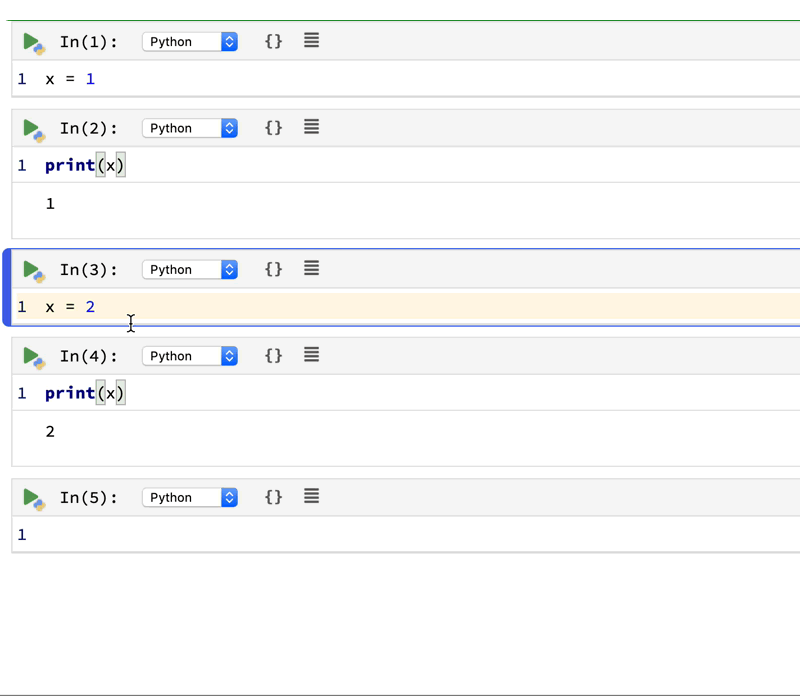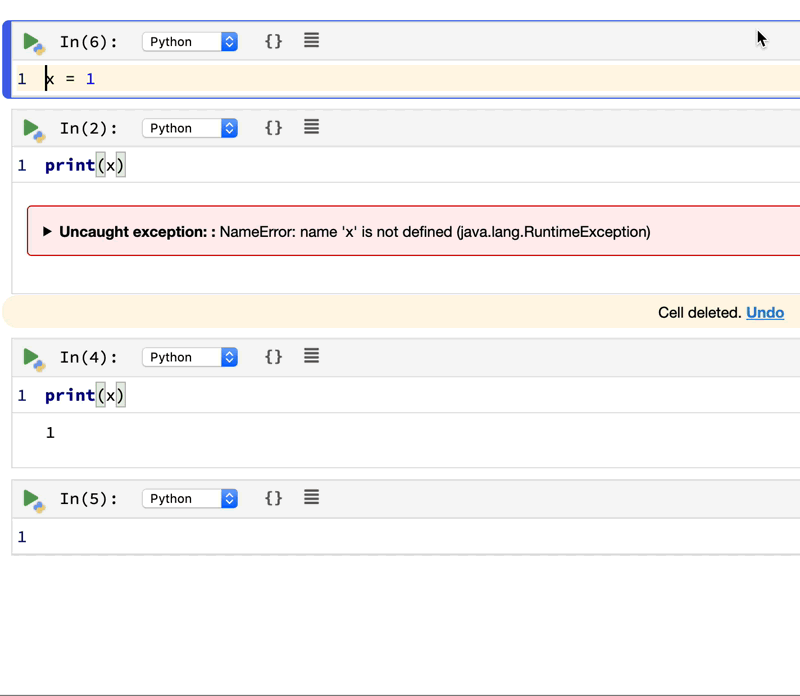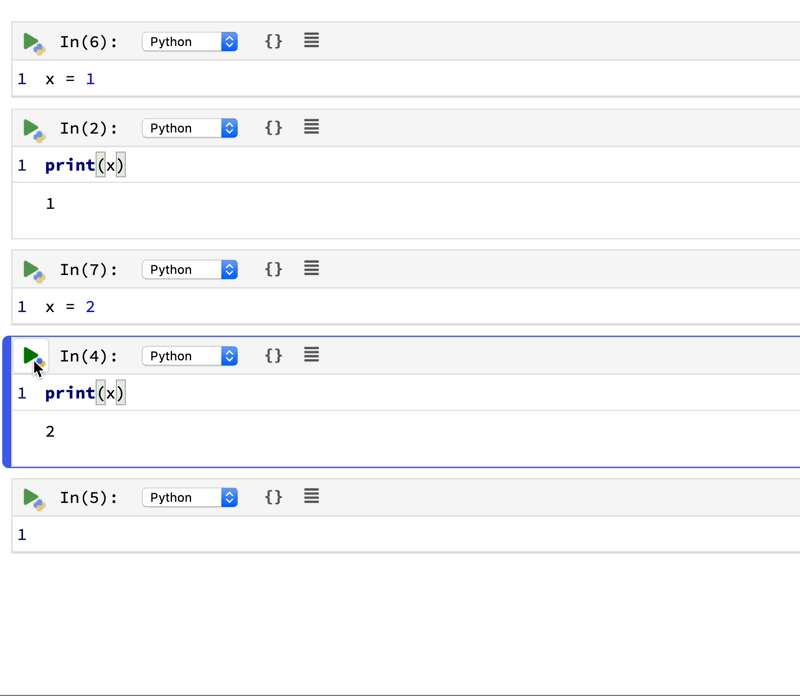
Simply put, Polynote is not using the good old REPL model for code execution. It uses its own code interpreter instead. The biggest difference is: for Jupyter Notebook that uses REPL, you can safely execute cells not in the order they are written. You can execute cell 3, then cell 2, then cell 1. It’s all up to you. This brings flexibility but decreases the sharability of the notebook. Polynote handles cell execution differently:
By keeping track of the variables defined in each cell, Polynote constructs the input state for a given cell based on the cells that have run above it. Making the position of a cell important in its execution semantics enforces the principle of least surprise, allowing users to read the notebook from top to bottom.
It seems to be more like you are writing a script instead of a notebook. You take more notice of making sure things are in order when writing it. But you get the benefit of consistent code results and better sharability. See the animation below:
Conclusion
We’ll see how well the industry will adopt Polynote but definitely it shows potential and making some sound decisions. One question is whether the big cloud platforms like GCP, AWS or Azure will adopt it. This is quite important because, without the support of these cloud platforms, people rely on them to do research/experiment won’t have access to Polynote and thus won’t use it.