
Kaggle is a good place to learn and practice your Machine Learning skills. It’s also a great place to find the proper dataset for your learning projects. I need a good classification NLP dataset to practice my recently learned fast.ai lesson, and I came across the Toxic Comment Classification Challenge. The competition is held two years ago and has long concluded, but it doesn’t hurt to submit my scores and see how well I did. This is one of the things Kaggle is great for since in the real world, it will usually be much harder to know how good or bad your model is, whereas, in Kaggle, you’ll see clearly where your performance is in the Leaderboard.
The Data Set
This competition is held by The Conversation AI team, a research initiative founded by Jigsaw and Google (both a part of Alphabet). Its goal is to find out the best model that can classify multiple toxicity types in comments. The toxicity types are:
toxic severe_toxic obscene threat insult indentity_hate
Comments are given in a training file train.cvs and a testing file test.csv. And you’ll need to predict a probability of each type of toxicity for each comment in test.csv. It is a multi-label NLP classification problem.
Look at the Data
Let’s first take a look at the data. We need to import the necessary modules and do some logistics to set up the paths for our files.
import numpy as np *# linear algebra*
import pandas as pd *# data processing, CSV file I/O (e.g. pd.read_csv)
*from fastai.text import *
from fastai import *
Notice here we imported everything from fastai.text and fastai modules. Are we against the software engineering best practice here? Actually, not quite. It’s rather a deliberate move in a more iterative and interactive data science kind of way. With all the library available, I can easily test and try different functions/modules without having to go back and import them every time. It will make the explore/experiment flow much more smoothly. But I digressed, let’s load the data and look at it:
# Kaggle store dataset in the /kaggle/input/ folder,
path = Path('/kaggle/input/jigsaw-toxic-comment-classification-challenge/')
path.ls()
# the /kaggle/input/ folder is read-only, copy away so I can also write to the folder.
!mkdir data
!cp -a {path}/*.* ./data/
!ls data
# make sure everything is correctly copied over
path = Path('/kaggle/working/data/')
path.ls()
# read in the data and have a peak
df = pd.read_csv(path/'train.csv')
df.head()
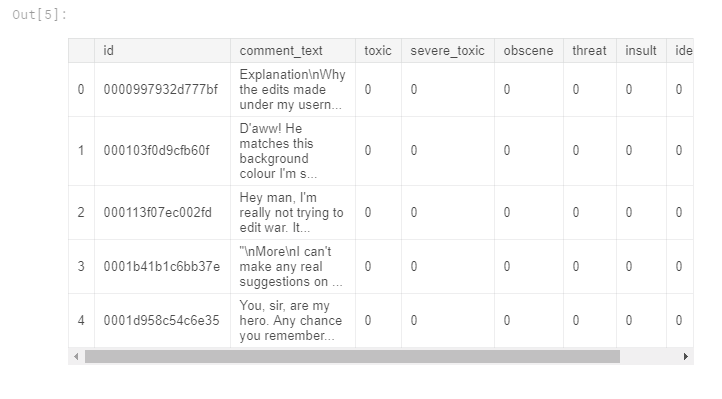
The toxicity types are one-hot encoded
The toxicity types are one-hot encoded
The comments are in comment_text column and all toxicity types are ‘one-hot’ encoded, we’ll have to do something about it to make it fit into our model later.
Have a look at one comment
Have a look at one comment
Transfer Learning: Fine-Tune Our Language Model

We’ll use transfer learning for this task, to do that, we’ll use a pre-trained model based on Wikipedia called wikitext-103. It is a model that’s already trained from the Wikipedia dataset(or ‘corpus’ in NLP terms) to predict the next words from a giving unfinished sentence. We’ll leverage the ‘language knowledge’ the model already learned from the Wikipedia dataset and build on top of that. To achieve the best results, we’ll need to ‘fine-tune’ the model to make it learn a bit from our ‘comments’ dataset since what people say in the comments are not necessarily the same with the more formal Wiki. Once the language model is fine-tuned, we can then use it to further do our classification task.
Now let’s load the training data into the fast.ai databunch so we can start training the language model first.
bs = 64 # set batch size to 64, works for Kaggle Kernels
data_lm = (TextList.from_df(df, path, cols='comment_text')
.split_by_rand_pct(0.1)
.label_for_lm()
.databunch(bs=bs))
We use fast.ai’s Data Block API for this task. It is a very flexible and powerful way to address the challenging task of building a pipeline: loading your data into the model. It isolates the entire process into different parts/steps, each step with multiple methods/functions to adapt to different types of data and the ways data is stored. This concept is a lot like the Linux philosophy, highly modulized and with each module only do one thing but really really well. You are free to explore the wonderful API here, for the above code though, it does the following things:
-
Import data from Pandas DataFrame named df, tell the model to use comment_text as input (TextList.from_df(df, path, cols=’comment_text’))
-
Split the training dataset into train/validation set by random 10/90 percent. (.split_by_rand_pct(0.1))
-
Ignore the given labels( since we are only fine-tuning the language model, not training the classifier yet) and use the language model’s ‘predict next word’ as labels. (.label_for_lm())
-
Build the data into a databunch, with batch size bs. (.databunch(bs=bs))
Now let’s look at the databunch we just built:
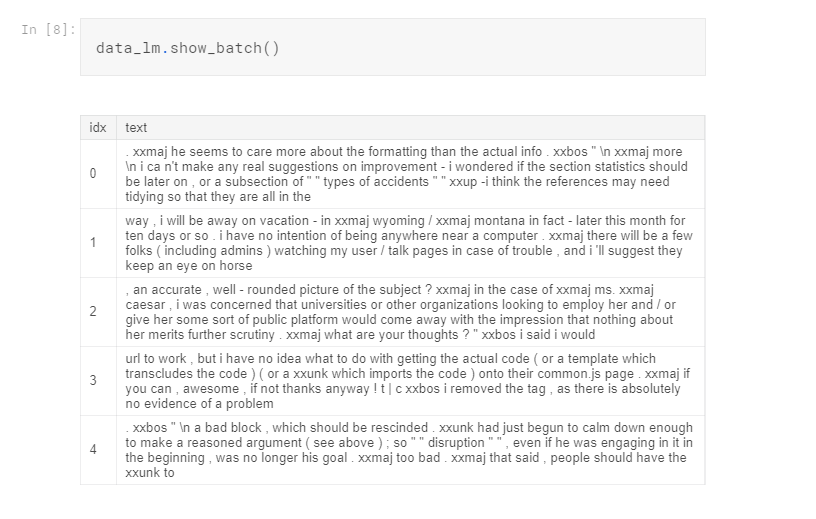
Notice we lost all the toxicity types
Notice we lost all the toxicity types
Notice that the databunch doesn’t have all the toxicity type labels since we are only fine-tuning the language model.
OK, time for some typical fast.ai learning rate adjustments and training:
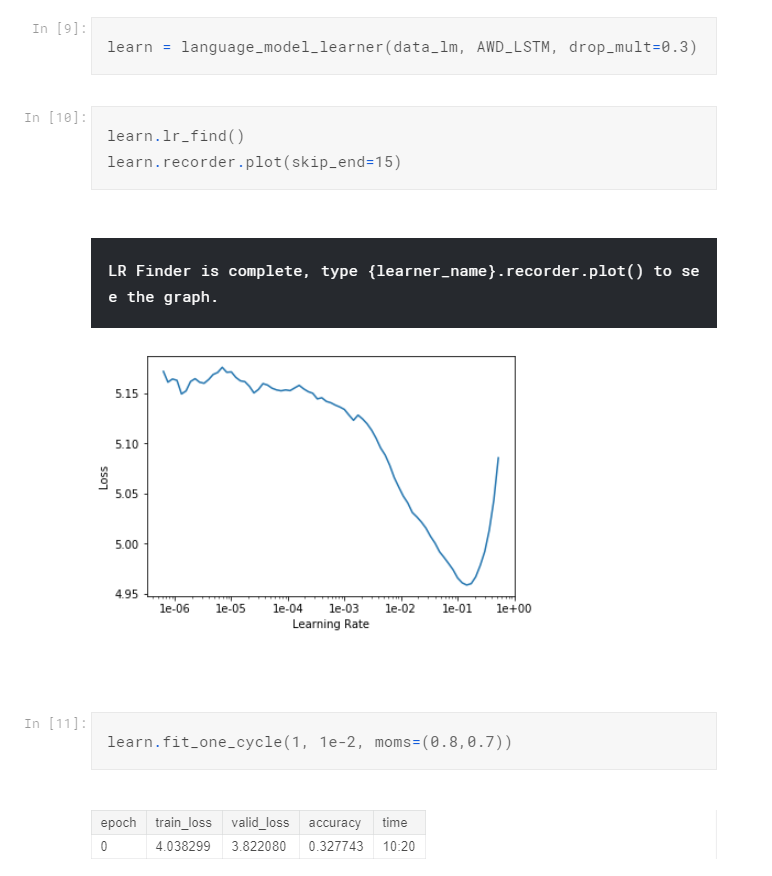
We put our databunch into a language_model_learner, tell it the language model base we want to use (AWD_LSTM) and assign a default dropout rate of 0.3. From the LR Finder graph, find the biggest downward slope and pick the middle point as our learning rate. (For a more detailed explanation of how this ‘fit_one_cycle’ magic is done, please refer to this article. It is a SOTA technique of fast.ai that combines learning rate and momentum annealing). Now we can ‘unfreeze’ the model and train the entire model couple of epochs:
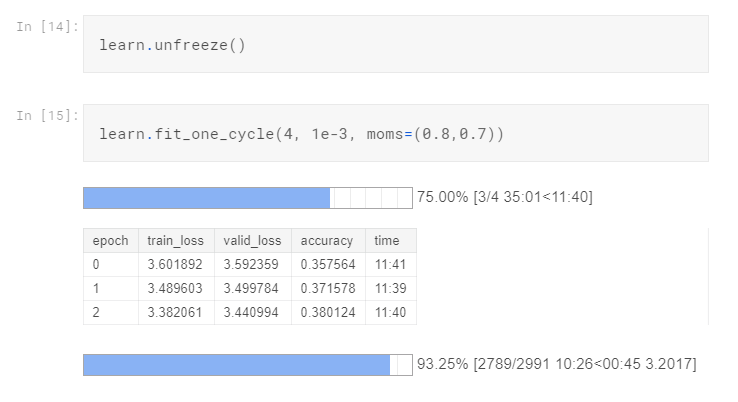
We can look at one example of how well the model did:
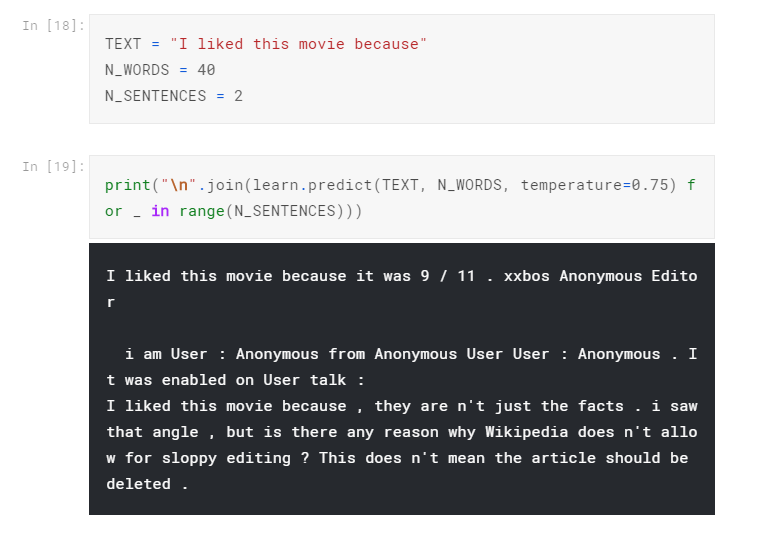
The result is hardly optimal. Ideally, we need to train a bit more epochs but for this Kaggle Kernel, I was running out of GPU quota so I stopped at 4. The result definitely has room to improve and you can try it yourself. Anyway, what we want from the language model is the encoder part, so we save it.
*# save the encoder for next step use*
learn.save_encoder('fine_tuned_enc')
Transfer Learning: Training the Classifier
Let’s read in the test dataset:
test = pd.read_csv(path/"test.csv")
test_datalist = TextList.from_df(test, cols='comment_text')
Again, build our databunch:
data_cls = (TextList.from_csv(path, 'train.csv', cols='comment_text')
.split_by_rand_pct(valid_pct=0.1)
.label_from_df(cols=['toxic', 'severe_toxic','obscene', 'threat', 'insult', 'identity_hate'], label_cls=MultiCategoryList, one_hot=True)
.add_test(test_datalist)
.databunch())
data_cls.save('data_clas.pkl')
Please note the difference this time:
-
We now use all our toxicity styles labels (.label_from_df(cols=[‘toxic’, ‘severe_toxic’,’obscene’, ‘threat’, ‘insult’, ‘identity_hate’],label_cls=MultiCategoryList, one_hot=True),)
-
We added our test set here. (.add_test(test_datalist))
Now look at our classifier databunch :
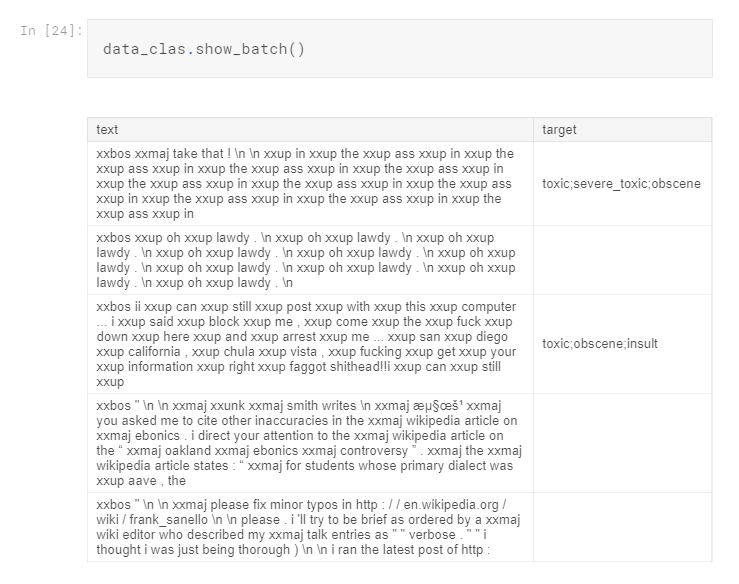
Note that now we have all the toxicity styles labels
Note that now we have all the toxicity styles labels
Finally, time to put everything together! We’ll put the databunch into the text_classifier_learner model and load the encoder we learned from the language model.
learn = text_classifier_learner(data_clas, AWD_LSTM, drop_mult=0.5)
learn.load_encoder('fine_tuned_enc')
Again, find the best learning rate and train one cycle:
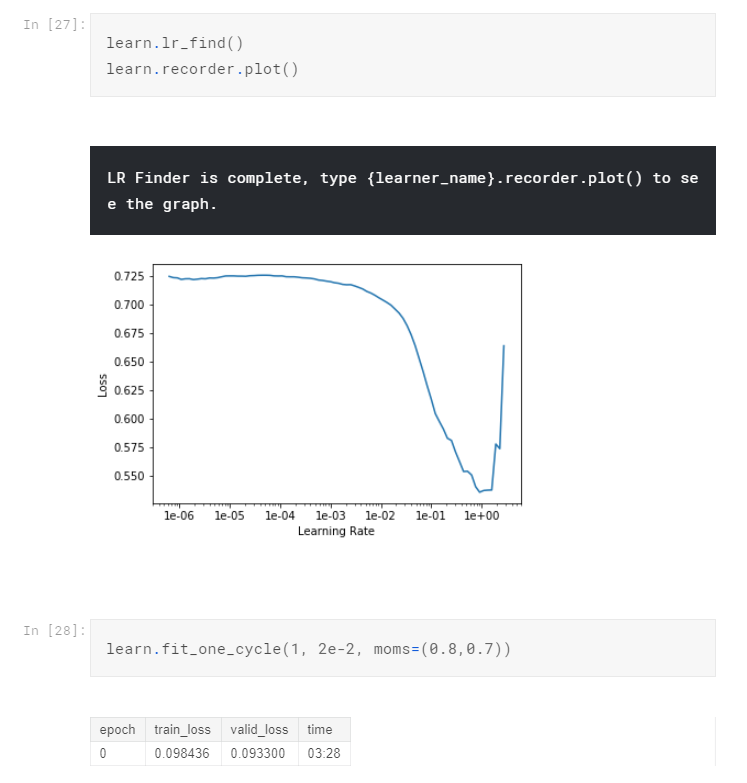
Train a bit more cycles and unfreeze:
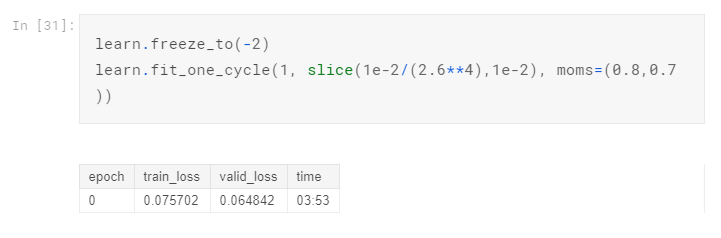
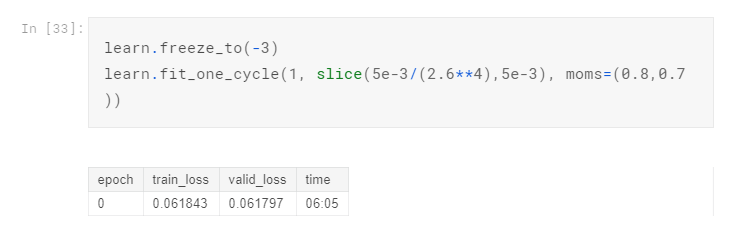
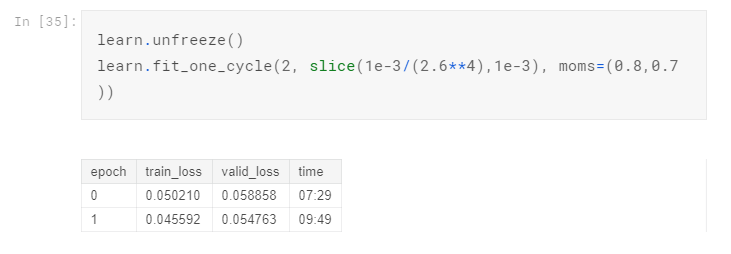
See the results:

Off by one, but overall the prediction is OK. For the purpose of reference, I submitted the prediction to Kaggle and get a 0.96583 Public Score. The result is not optimal but like I said I didn’t train all the way due to limited GPU. The purpose of this article is to show you the whole process of using fast.ai to tackle multi-labels text classification problem. The real challenge here is to load the data into the model using Data Block API.
Conclusion
I hope you learned a thing or two from this article. Fast.ai is really a lean, flexible and powerful library. For the things it can do (like image/text classification, tabular data, collaborative filtering, etc.), it does it very well. It is not as extensive as Keras, but it’s very sharp and focused. Kind of like Vim and Emacs if you are familiar with the command line text editor war. 😜
You can find the Kaggle Kernel here.
Any feedback or constructive criticism is welcomed. You can either find me on Twitter @lymenlee or my blog site wayofnumbers.com.