
This accident actually happened about one and a half years ago, it happened on an Uber’s self-driving car, and it took one women’s life. This is a serious reminder to the AI community that the work being done carry a lot of weights, sometimes other people’s life.
A Flash Back of What Happened

This terrible accident happened on March 19, 2018, late in the night. An Uber self-driving car, running in autonomous mode with a safety driver behind its wheel, hit and killed a woman in Tempe, Arizona. You can find the detailed investigation results here. From the dash-cam and internal driver-seat camera footages, the accident happened on a poorly lit road with a speed limit of 40 mph. The safety driver was watching her cellphone (possibly watching Hulu) right before the car hit the woman. According to the telemetry obtained by Uber after the crash, the algorithm classified the women as ‘ unknown object’, then ‘ vehicle’ and then ‘bicycle’ during the process and the indecisiveness led to very late action(order the car to stop 1.3 seconds before the crash) which eventually led to the tragedy. Neither the Lidar or Radar sensor triggered nor the paid safety driver picked up the pedestrian. Either one of the above measures, if worked, could have saved the woman’s life. This accident has passed for some time and Uber has already resumed testing their self-driving cars on the road. Yet it might be valuable to contemplate a bit more from a Data Science point of view on what went wrong and what flaws were in Uber’s self-driving system that caused this tragedy.
Possible Flaws of the Self-Driving System
Before diving deep into the potential flaws of a self-driving system, it’s worth noting that self-driving car is actually the most-advanced application of AI that’s is the closest to AGI(Artificial General Intelligence). Driving is a very complex and potentially quite dangerous act to begin with. The environment a self-driving car has to deal with could be very complicated that require all kinds of situation awareness: other cars, pedestrians, bikes, traffic signals, signs, weather, road situations, etc. It’s true that great progress has been made on artificial intelligence these years, but is it good enough for this task? No matter the answer, all possible issues should be thoroughly addressed and tested, no stone unturned. This leads to the first and most important aspect of the system, the team developing the self-driving car.
Applied Artificial Intelligence Development Teams Sometimes Are Under-staffed with Engineers
Photo from https://365datascience.com
You don’t necessarily need to have a master’s degree or Ph.D. to do data science work, but the statistics show that the majority of the data scientists in the industry at least have a master’s degree. A big part of them even has a Ph.D. This is very well justified since Artificial Intelligence and Data Science are not trivial areas. It requires many years of training in math, computer science and a wide variety of technologies. This has been the consensus of the industry. A consensus so strong, sometimes people forgot other parts of the equally important roles to make a real-life AI project such as self-driving cars successful. Most importantly, engineering. If what required is to prove the performance of an algorithm for some single-purpose task ( like Radiology Image Recognition), you don’t need much engineering power. A solid Data Scientist will probably do the job well enough. If developing and deploying a machine learning application on the web to analyze comments sentiment is the task, then you might want to hire more solid developers and DevOps engineers to make sure the application is well structured, carefully coded and easily maintainable. So what if you want to build a self-driving car system that needs to sustain many hours without any incident in the real world? You might want to hire car designers, regulatory specialists, car safety experts, physicists, and some top-notch data scientists to create a diversified team so the task can be properly tackled. For this Uber self-driving car incident, one reason the self-driving car failed to respond quickly is that neither of the Lidar and Radar systems picked up the woman crossing the street. Uber changed from using 7 Lidar sensors to use only one on top of the car, which creates some ‘blind spot’ around the car. What is the reason for that? Are there any other engineering debts that need to be covered for safety reasons? Are there any design flaws in the placement of the sensors? Are there any interference issues in the environment? Does the communication channel between sensors and the central computer work smoothly? This is not to say these are the exact cases, it’s just these are the question need to be asked and addressed, and the best type of talents to address these issues are engineers, not data scientists.
Small Data

Now small data IS a data science issue to address. What is means is to build an efficient model, a large amount of data for each situation would be required to train the model. But sometimes imbalanced data issue is hard and costly to solve. Take the self-driving car as an example. When it comes to safety, what matters most is when things do go wrong. The more data for different accident types are collected, the better it will be to train a model that are robust enough to handle itself in all conditions. But unlike airplanes with the black boxes, car accident data is much harder to gather. Firstly it’s hard to ‘generate’ or ‘create’ an accident. Secondly, not all cars are equipped with sensors to gather those data while the accident happens(some more ‘smart’ cars like Tesla probably can, but the majority of the cars are not there yet). As data scientists, it’s a consensus that the bottleneck for a high-performance model usually is not the algorithm, but the data. Without enough relevant data about car accidents, it will be very hard for the data scientists to develop a model that can handle those accident types very well. To make a self-driving car system that can drive a car on the street, turn, accelerate/decelerate properly is not the hardest task. The hardest task is creating a model that handles all the accidents well, without enough data.
Handle Edge Cases
This is actually a more extreme case of the small data issue, but worth single it out. One rule of thumb for safety is to consider all the edge cases that things could go wrong and be prepared for it. This is less of a problem for humans since a human has common sense and a broader situational awareness than any algorithms, so humans are more prepared to handle the edge cases, but algorithms are usually not sophisticated enough, thus need more work.

Photo from https://www.chron.com
Let’s imagine some of those edge cases.
**Flood on the road: **Humans will back off, or choose some flatter grassland to cross the flood, but if cars are only trained on driving on road, it cannot handle this correctly.
Very slippery road: Humans will change their driving patterns and handle turns very gently to avoid slipping. Or stop and put the anti-snow chain, AI will be hard to achieve the same level of flexibility.
Road with graffiti on it: Human can easily know what’s going on and will not make mistake but AI if not trained by road with graffiti on, it might mistake the graffiti with real road guidelines.

The list goes on and on. If you can think of other edge cases you encounter from your past driving experience, please leave a response below. The bottom line is, driving in real-world need way more sophisticated system to handle all weird cases and humans are very good at that (thus taking that as guaranteed). While AI needs to train on every case. No shortcut. The ability to come up with those edge cases and design the self-driving system around it will gain robustness and safety scores and possibly gain an edge over the competition.
Where to Improve
So should self-driving car accidents stop the development of the technology? Of course not! The technology has huge potential in saving a lot of lives. The AI might be biased or not sophisticated enough, but it has one treat that humans don’t. They never become emotional, or reckless, or sleepy. Done right, it should out-perform humans on safety in most situations, but obviously it is not there yet. So which parts of the process can be improved? (I’m not a self-driving car expert myself and just wanted to explore possibilities in this article so take the following with a grain of salts. If you have better ideas, please feel free to leave a response below!)
Testing Process
Again, before delving deep into technology, people-related issues need to be tackled first. One thing that was especially surprising about the incident is the car actually HAS a safety driver. The whole thing could have been avoided if the safety driver did her job and not looked at her cellphone and kept her eyes on the road. It’s not that hard to do but her failure to do so indirectly costs a life. This has nothing to do with technology but has everything to do with how the self-driving test process can be improved. It’s a good start to put a paid safety driver behind the wheel to add another layer of safety for the test, yet humans make mistake. Since the car already has an internal camera monitoring the driver, why not develop an algorithm to monitors her/his behavior and give alerts/scores when her/his eye wonders off the road?
Hardware
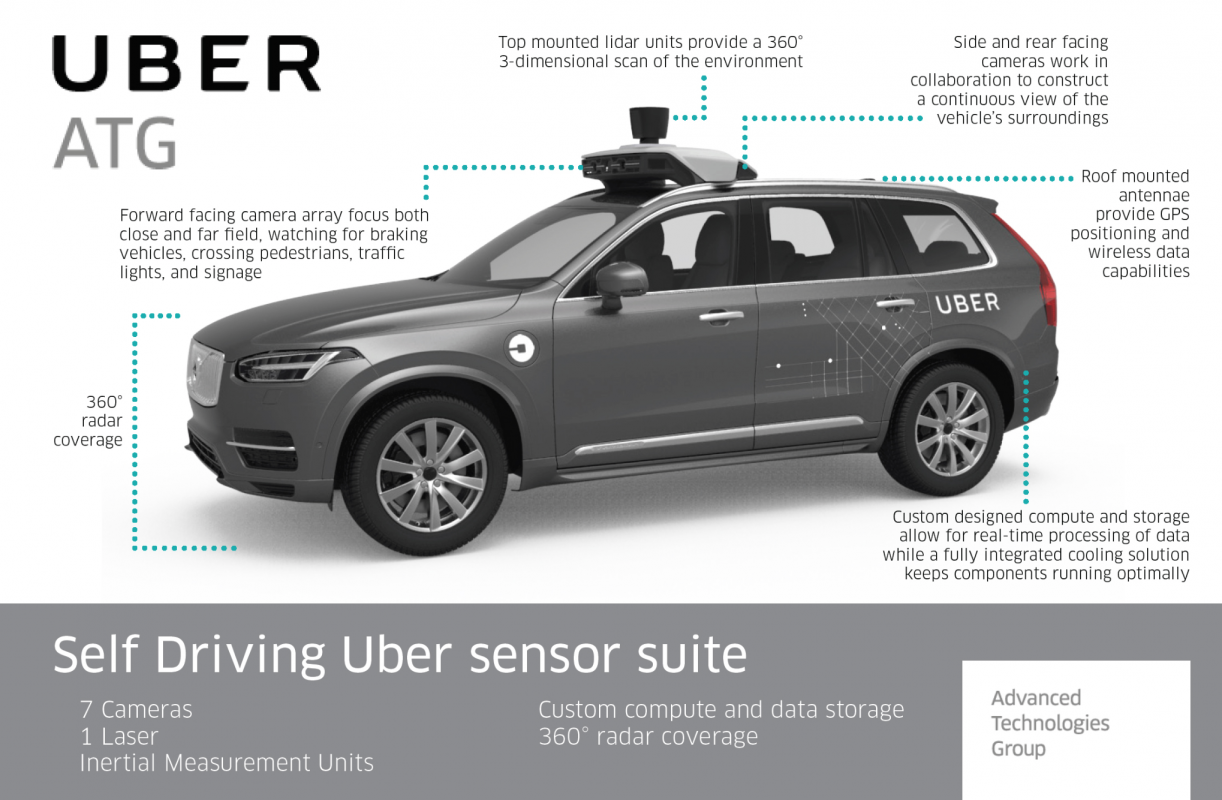
Photo from https://labs.sogeti.com
The Lidar/Radar fails to trigger in this accident. What was the reason? Will add more than one sensors work better? Adding more types of sensors? Optimize the position of the sensors? The sensors need to work on all weather conditions. Hot, code, snow, extreme sunburn, windy, etc. If not, have a backup plan. Prepare for the extreme.
Software
Is the central driving system has a prioritized control system, means some special events triggered on the sensor or image recognition system will cause the car to immediately stop to avoid severe accidents, surpass all other driving control system. ( e.g. hard code assured clear distance ahead) The prioritized system needs to be carefully designed and adjusted for maximum safety.
Algorithm
One thing that is very essential for all machine learning models is the validation set. A good validation set defines how well the model generalizes and thus heavily determines the success/failure of a project in real life. This also applies to the self-driving car. What would be a good validation set here? Well, driving a car is not as simple as our classifier problem thus not very clearly defined. This is exactly where the problem is. Should all the self-driving car companies and regulatory bodies team up together and develop a good ‘test routine’ that captures all the extreme situations, edge cases, test scenarios, automatic test software, etc., to effectively serve as the ‘validation set’ for self-driving cars? I think a collateral consensus and efforts here from all players is essential and less explored.
Final Thoughts

Photo by Ciprian Morar on Unsplash
No matter how much progress has been made on self-driving cars, sometimes it felts like just scratching the surface and the size of the iceberg lurks beneath the water remains unknown. Also, the self-driving car accident usually gets high media attention. According to Wired, nearly 40,000 people died in road incidents last year in the US alone, but very few (if any) made headlines the way the Uber incident did. Unfair? No really. This is actually a good thing. Strict and close scrutiny is a good thing to push the limits of how safe the self-driving car can be. Because it’s human lives that are on the line.
Update: The final result of the investigation is out on Nov 20, 2019. You can refer to this article by The Verge.